AI在金融领域的应用越来越系统、深入,但总体来看,仍有许多不尽如人意之处。智能金融是数字金融的升级。我们多年以前就开始发展数字金融了,但数字金融的发展似乎还未完全到位,智能金融就已经来了。
政府可以通过建设好数字基础来推动智能金融的发展。与此相关的问题有很多,包括数据的权属、保密责任、如何应用、如何脱敏等,而只有政府能从合适的切入点围绕这些问题作出系统性规定,它愿意为社会、经济和科技发展做好基础平台和底层建设,也是最具权威、最有能力全面推动相关工作的主体。
我们现在讨论更多的是大模型,但有时小模型也很重要。小模型就是人类分解研究任务、降低难度的一种办法。一个人想精通全部领域可能很难,但聚焦较窄的具体专业领域反而做得到。大家都想当大将军,通晓十八般武艺,但十八般武艺也是一般一般练起来的,聚焦单个小领域的小模型或许能更灵活、深入地解决问题。不过,无论是大模型还是小模型,都需要完善的数据基础。
我最近读到新闻,上海等多地区出台了新规,只要住客提供适当的身份证等信息即可,禁止 “强制刷脸”才能入住酒店。计算机拥有的海量数据和高速处理能力其实蕴含很大的风险,从计算机科学本身的角度看,所谓的在线交易保密几乎是不可能的,没有任何信息经由网络传输而不可破解,数据只要产生了足够巨大的经济利益就会被追逐。这是这一行业面临的不可解的问题。
按此思路,我一直认为,发展数字金融需要建设一部分离线系统,两方不通过同一个网络传达信息,以降低被攻击或窃取信息的风险,但这目前还不是很成熟。我讲这点只是想提醒,尽管数字金融是一个很热门的体系,但依然存在一些基础性问题,首先就是数据问题。
在计算机涉及的要素中,除了数据,还有算法、算力等。
算法本质是一种立法。对于一件事如何判断、法院如何裁定,立法制定了一套系统规则,而算法就是计算机系统中的立法。以算法公司或计算机公司开发自动驾驶算法为例,如果遇到类似“电车难题”的复杂情形,如何判定向左还是向右?这可能最终会成为一个必须通过系统性的社会立法来解决的问题,它不是一个简单的数据工程师面临的算法问题,也不是科学家面临的解题方法问题。强行“刷脸”也是如此,相关行为主体是否要对其负面后果负责也是很大的问题。
推动AI的发展和应用还应思考算力问题。有观点认为,未来AI甚至可能会耗尽全世界的电力。AI发展需要消耗巨大的电能,大模型ChatGPT第一版约有上亿参数,第二版有十亿参数,第三版有百亿参数,第四版有千亿参数,现在参数规模已达万亿水平。这似乎是反摩尔定律的:摩尔定律认为,随着计算机科学的迅速发展,成本会指数级降低,能力则越来越强。按此逻辑,ChatGPT的改进产生了多大的代价?是参数增加了一个量级,即十倍。假设参数处理所需时间是线性增长的,那么随着工作量的指数级别增长,所耗能量也在相应扩大。
计算机理论中存在一个可计算性的问题:算法或许正确,也可以一直计算下去,但计算过程永远无法完成。数值预报中就存在类似问题。我们使用流体力学中的数学模型进行数值预报,当模型与天气变化同时启动,如果计算速度快于天气变化速度,那么计算是有效的,如耗时1小时计算出24小时后的天气状况;但如果模型过于复杂,对于24小时后的天气状况预测,需要48小时才能计算出来,那么预报就没有用了。AI模型要解决的问题比数值预报还要复杂得多。
在未来科技发展方向的判断和程度的把握上,我们可以积极推进AI的应用,同时也要建立好数据制度,并进一步思考计算机是不是“大力出奇迹”等问题。
例如,AI的“涌现”究竟是什么?我们不停地转动万花筒看到的花样就是一种涌现,但这样的涌现不一定就代表某种规律。ChatGPT的推理基于的是现象同时出现的统计规律,这并不是一种绝对性的关系,没有真正的逻辑根据,所以可能会出错。小模型则是基于逻辑进行推理判断的。从逻辑学角度看,做出判断要依赖的是具有全部概括性的规律,不涉及个别选择的问题,但生成式AI则是根据既定原则生成大致的结果,这个结果无法判断真假。例如,律师使用ChatGPT研究案件,却获取了捏造的案例。
那么未来,我们是否还需要开发新的AI软件,对所生成内容的真伪进行验证?这又会花费更多时间。
这些都是很有趣也很实际的角度,我们要冷静、客观、全面地思考。
(作者系中国金融四十人论坛常务理事、 中金公司前总裁兼首席执行官、清华大学管理实践访问教授)
第一财经获授权转载自微信公众号“中国金融四十人论坛”。











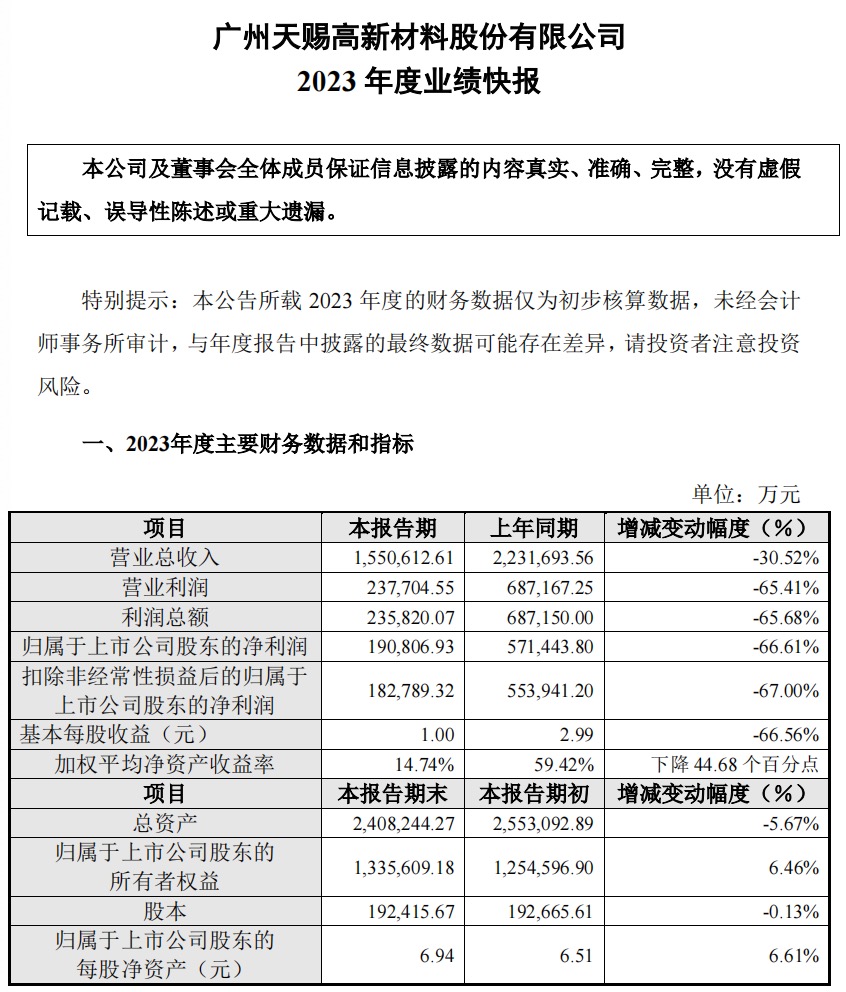
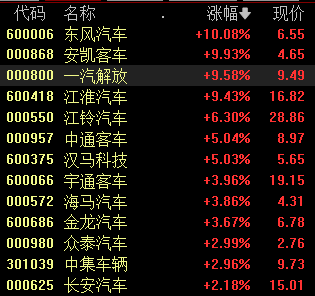


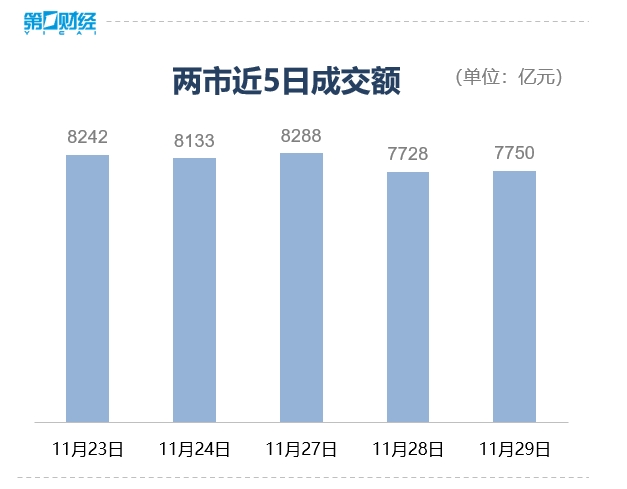

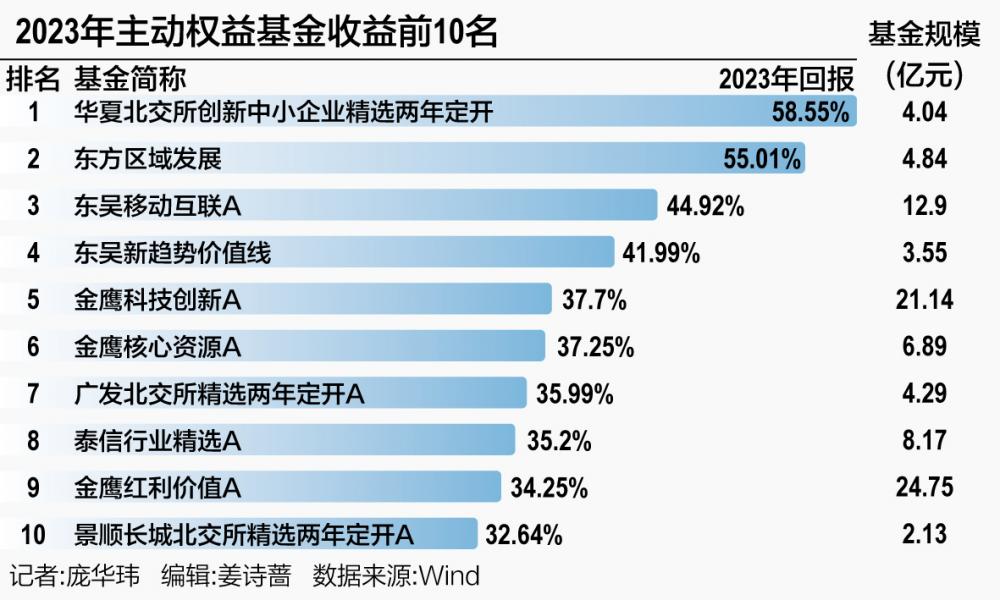





暂无评论内容